DB Modernization Plan
Summary Table
1.4. Standard program coding problems
1.5. Supplementary database problems
2.2. Very first step - Discard unused objects
2.4. Verify the integrity of the database.
4. Decide implementation method
5.2. Relationships means new columns
5.3. Relationships means new foreign keys
6. Prepare database to the new languages
6.3. Database administrator role
6.8. The abstraction layers begin to appear
7. Complexity implicit or explicit?
7.3. Case 0: no view + new program is monolithic (spaghetti code)
7.4. Case 1: new program less spaghetti – less code, more consistency
7.5. Case 2: business constraints in the database – less code more quality
7.6. Case 3: business constraints and security constraints in the database- more security
8.3. RPG-OA Open Access architecture Hypothesis
8.4. One solution: dive deeply into the old code
8.1. Can I add new constraints?
1. Where you are
1.1. Executive Summary
Does your team still uses RPG3 programs with DDS files? Your technical debt is 25 years old.
Does your team still uses System-36 programs? Your technical debt is 40 years old.
It works, just the maintenance costs are extravagant.
|
|
A little technical for an executive summary. Let us change the explanation. During previous century, database files was just as rolodex: a stack of cards rolling on a cylinder giving access to each card quickly. Now, database files are in a database engine. The database engine is the guardian. It knows vocabulary and grammar. It is able to refuse typos and mistakes. We say it guarantees the quality of the database.
|

In the 90's RPG developer where alone on an island. They were alone to create and maintain application from Display to the DataBase and their mindset was programming. So everything out of the code was aside and not their first aim. If you add some technical constraint based on the hardware and the software of this time. This could explain that.
Another point is that IBMi need less resource than other environment and so less people to do the same Job.
The fact that the code is still working is another issue.
The technical debt is born there, in the 80's. The system was a twinax island, no need to think to security or consistence.
1.2. Introduction
In this chapter we present an example of a 5250 app that run for years.
In the following pictures, the color code is:
· Green for DDS/RPG
· Blue for SQL Tables
· Orange for SQL Functions
· Gold for SQL Views and new applications

1.3. An old 5250 application
It works for years, old users are happy with it.
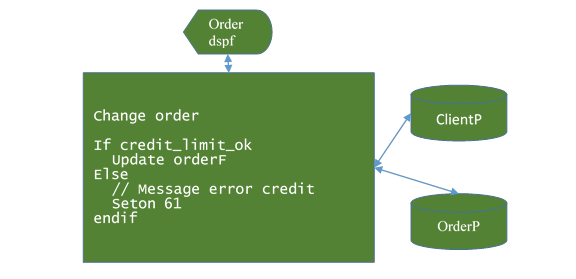
1.4. Standard program coding problems
This old RPG program has been converted up to RPG4Free. That's good. It is true for all of your programs?
Probably no. As most of the IBMI developers team,
· You have a mix of RPT3, RPG3, RPG4, RPG4Free,
· Business function (credit_limit_ok) and database function (update) are interleaved (spaghetti code), the code is a monolith,
· Database function (the update in the RPG program) address directly the physical files (DDS-PF or SQL Table) so reorganization of database is complex, it involves a lot of changes in the application (a lot of cost) for nothing new (no new feature).
1.5. Supplementary database problems
Your database also is old, as your programs (and your coders? no they are retired). It corresponds to optimization and performance rules that match the 90's years. This is the technical debt.
· In our example the Client file and the Order file contains status field and address fields but there is not “parent” table for them, so the values are duplicated (address in client and address of the commands of this client are often equal, but duplicated in each command).
This is how database was strongly optimized one century ago, but now we want to get back to a database (a few) renormalized.
|
Custno |
Custname |
Status |
Address1 |
Address2 |
City |
|
|
|
|
|
|
|
|
OrderNo |
Custno |
Custname |
Status |
Address1 |
Address2 |
City |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
· The address fields present a sophisticated problem: most address in order table are just duplicates of the client address, but some orders does not use the default (client) delivery address.
And sometimes there are legal constraints: in some country it is forbidden to change a shipping document (including the delivery address) as soon as the document is published.
Your code contains at different places a process that decides (or not) to replicate the client address in orders, shipping, invoicing …
1.6. Evolution problems
· You think to rewrite Ordering as a web application. This web application should not be concerned by the problem of replicating the address. But existing code should continue to work, without being changed for nothing (or as less as possible).
· You may think to Open Access Handlers. This option is open if you have only RPG4. OAH is not supported neither by RPT3 or RPG3 nor by COBOL (sure ? verify). This option suppose your available source code is effectively the one used to compile programs. Since how long did you compile all your programs?
· You think to java as a replacement solution. Feed backs was bad. Search info from guys that was at various common. Some of them are guys that had to handle the performance issue. Search for how they solved it. This is a hot subject, new solutions may appears at any time. This document does not cover the subject.
· You may think to revamping or editor solution. It work …but you technical debt will be greater. Lipstick on a pig. It is not a road, it is a cul-de-sac. A technical cul-de-sac or a financial cul-de-sac.
It is vital for your business to assure the continuity of the service provided by your application: it is the way you win money. Whatever happens, the RPG programs should continue to work!
1.7. Conclusion
Your problem is largely common to most companies using personalized applications on IBMI.
You have accumulated so many different technologies that it is now difficult to keep maintenance costs at a reasonable level. All these technologies live together, due to the power of IBMI and IBM's agreement to maintain perfect execution of old code. This hides the technical debt.
Due to previous agreement, your development team is small and overloaded, permanently trying to turn off the fires of yesterday. There is no budget for the technical debt.
Do you ever have try/think to verify the integrity of your database?
Today's state of the art is a structured organization of the development with layers respected by program developers and database developers.
Where you are. Rainbow Spaghetti code isn't it?
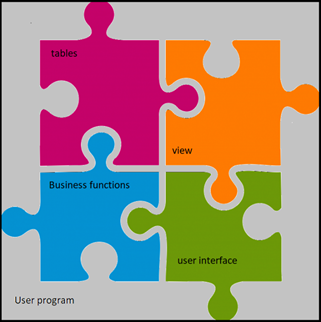
Where you go: the successive layers are independents from the others.
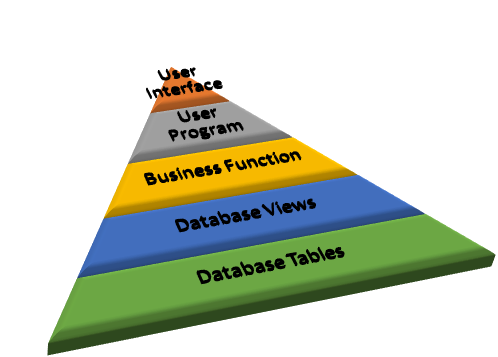
2. Prerequisites
2.1. Executive summary
You should do an inventory of current situation before launching any evolution project. The key to drive the project.
2.2. Very first step - Discard unused objects
Discard unused objects first
An average of unused objects is around 30 %. Don't rework them!
But don't add risks: just move unused objects in another library, and keep this new library in the library list.
Suggestion: reset the used day count, and run a periodic review to detect objects that finally are not unused.
2.3. Verify source code
Are you very sure the available source match exactly source used at compilation time?
Verify that your available source code last update time matches the compilation time of your programs.
Main code and also copies, for programs and files (and commands and menu … ).
At some time, you will need to recompile parts of your apps. Recompile and run an initial test of your application. Recommendation: record your test so you can replay it easily.
2.4. Verify the integrity of the database.
Integrity of the database is an uncivilized term for Quality of the data and Quality of the structure.
This consist into detecting the orphans (such as an order without customer), duplicates (two customers with the same customer number), and inaccurate data (alpha into numeric field, zeroed date, …).
Steps: Use database maintenance tools to
- Create a data model of existing PF files (IE a graphic representation of the database)
-
Retrieve probable foreign constraints. A foreign
constraint is an uncivilized term for
"explicitely declare that the customer field in file ORDERP should
exists in the file CLIENTP".
- Inspect these foreign constraints to detect orphans
- Create detection triggers to alert in real time the developers of a violation of integrity.
(it sends an alert in a message queue to keep developers advised that this foreign constraint has been violated just now (real time) in this program at this line number (the source code line number, within the call stack)).
2.5. Conclusion
The state of you programs is not your main problem. To have a chance to build a new application, you need a database that guarantees its integrity. Good news: it is possible.
3. Start with the foundation
In this chapter we will look at various aspect of database modernization.
3.1. Executive summary
There is a logical order on actions to modernize an application.
Start with the foundation: modernization of the existing database.
And to rework the database, there is also a logical order on actions.
Start by discovering/reengineering.
BTW, whatever happens, the current application (RPG programs) continue to work!

3.2. Modernize DDS-PF
Target: Modernize the DDS-PF files, with nearly no impact on existing application.
Method: transform the DDS-PF to
1) A DDS-LF with same name and structure and access path and DDS-keywords.
2) A SQL table for the existing data, plus identity and audit columns
This is the method preconized by IBM in the modernization redbooks
Modernizing IBM i Applications from the Database up to the User Interface and Everything in Between
https://www.redbooks.ibm.com/redbooks/pdfs/sg248185.pdf
IBM System i Application Modernization Building a New Interface to Legacy Applications
https://www.redbooks.ibm.com/redbooks/pdfs/sg246671.pdf

BTW, the SQL table get new columns, mainly for audit. One of them is the famous “FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP”, the key field for optimistic lock in new stateless applications (client-server, web, java, php, …)
Effect:
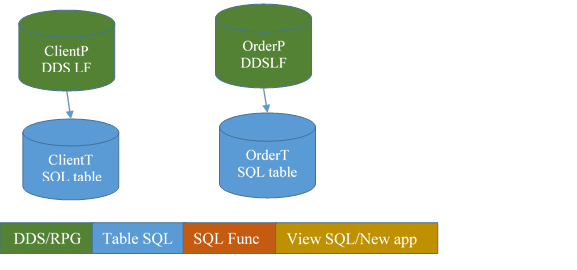
The RPG programs continue to work because the RPG programs just require a format and an index. Both provided by either a DDS-PF or a DDS-LF. This is the reason why the surrogate method works well.
3.3. Create missing parents
Target: retrieve / discover relationship between tables (manually or with tools … )
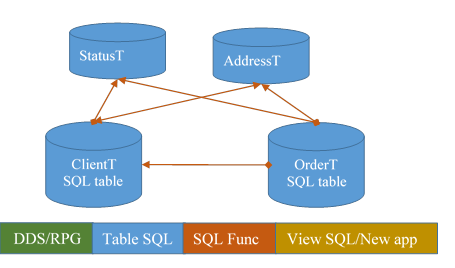
In our example, the files ClientP and OrderP have a Status column, but the exact list of all the status is described/verified only in the programs. Integrity requires an explicit list in a table.
Same issue with the addresses.
Create the missing parents so the process to add relationships to the database can discover a relationship between Parent and Childs.
How to discover a field requires a parent table?
1- Your knowledge of the application is the first filter
2- Counting the duplicated values in the studied field is a confirmation.
3- Reading how the RPG programs verify the fields is another confirmation.
These tables are populated (on DEV machine), to allow the process "add relationships to the database" to discover something
The RPG programs continue to work.
3.4. Discover relationships
Target: add relationships to the database.
With a manual (exhausting, tedious, boring, needing a lot of days) or automated inspection (let the tools doing the hard work, learn from it, do only the validation).
Find in column data
or column name
or column header
or column text
or DSPPGMREF
a probable
link
clue
sign
with another column which is a key column (unique primary key) of another table (the parent table).
The enormous quantity of possible files associations will push to some sort of optimizations. For example, when two files are never used both in at least one program, the probability there is a link between them is low. In our case, the new tables are not known by existing code, so the discovery process between any existing file (as child) and the newly created status file (as parent) concerns all the files.
The RPG programs continue to work.
Faire un vrai modele xcase base DDS , + copies d'ecran
4. Decide implementation method
This chapter present data evolution
Next chapter will present structure evolution.
4.1. Executive summary
Each case is a particular case (we are discussing of database tables evolution), each step should happens at the right time. Sometimes quickly, sometime later.
And don't forget: Whatever happens, the current application (RPG programs) continue to work!
4.2. Populate immediately
The table StatusT contains a few records that change rarely: this table will be populated in production servers, and the implementation method hasIn this chapter we describe how it is possible to implement relationships to detect when a program sets erroneous status when a record is added/changed into a child table (ClientT and OrderT). Without disturbing the existing application, this is a development problem, not a user problem.
4.3. Populate later
The table AddressT will contain a lot of records, that changes often. They comes from ClientT and OrderT.
But these data should stay in ClientT and OrderT because the DDS-LF ClientP and orderP require the address fields to be in the underlying table.
If the table AddressT is populated immediately in production servers, the data are one time again duplicated, and never read.
So the correct decision is to postpone deduplication of ClientT address and OrderT addresses later. By this, making useless for now the loading of anything in the table Address on production servers.
4.4. Conclusion
In our case, the referential constraint to StatusT will be correctly evaluated because the parent table (StatusT) is correctly populated, but the referential constraints to AddressT will always evaluated to Null because the parent table (AddressT) is empty.
The structure will evolve, but the data will stay still at the same place.
The RPG programs continue to work.
5. Implement relationships
In this chapter we describe how it is possible to implement relationships in a database without disturbing the existing application even when the new parent tables are not populated. Populating the new tables is another task, see next chapter.
5.1. Executive summary
There is a logical order on actions to rework the database. Continues with some normalization.
And don't forget: Whatever happens, the current application (RPG programs) continue to work!
5.2. Relationships means new columns
New fields and constraints in ClientT:
· FK (Foreign Key) to StatusT
· FK to AddressT for the client address
New fields and constraints in OrderT:
· FK to ClientT
· FK to StatusT
· FK to AddressT for the delivery address and for the invoice address
Add these fields to the sql tables ClientT and orderT
5.3. Relationships means new foreign keys
These foreign keys are based on new fields: DB2 works largely better when the relationships are based on identity (an identity field is just a long integer, unique).
So the implementation steps are
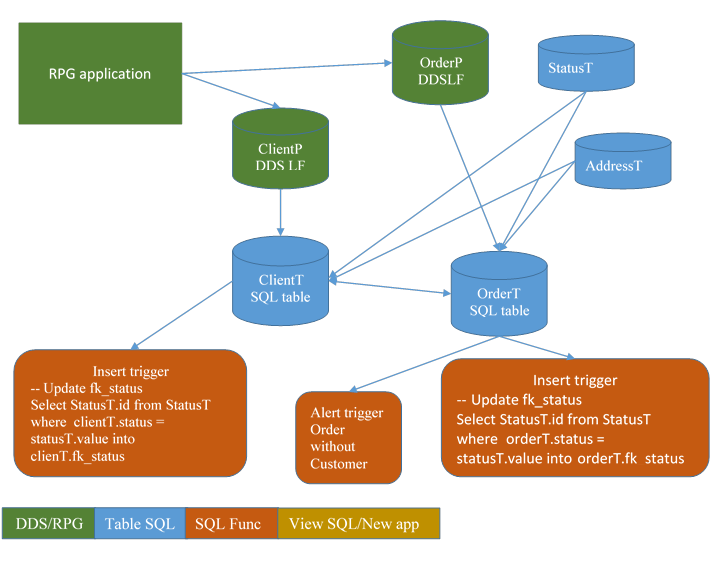
- In the child table, add a field to host the identity of the parent
- The maintenance of the relationship should be hosted in a trigger, we want to change nothing in the current application.
- The integrity violation triggers send alert in real time to the developers about a program violating integrity (users are not disturbed with this old issue).
Add the foreign keys and the triggers to the ClientT and orderT tables.
Once relations are implemented, the child files now have triggers. The task of these triggers is to maintain these new fields (that does not appears in the DDSLF clientP and orderP) when the DDSLF ClientP and orderP are updated by the existing application.
5.4. First side effects
Now the relationship exists in the database.
Warning:
· Relationship and triggers may means journaling and handling of transaction, commit and rollback. Be careful when you add a relationship or a trigger in the database. This document does not cover the best practices to add commitment in an application or to create triggers that does not promote referential integrity errors.
· You may also have side effects if you do CPYF: copying records to OrderT or OrderP may create errors if order status is not known in table StatusT (when the relationship will restrict the update, in a near future). You may also have problems with CPYF if the data in DDS files are inconsistent: the SQL engine check data consistency at write time when the DDS engine check them at read time.
· The restore commands will also handle the constraints between tables. No problem with a global save / restore of a schema. But with a standalone SAVOBJ of only one file.
· Updating the files of the application on the production server should also handle the constraints. Doing that manually is a practice of another century.
Transferring to QA or prod an application with true relationships is complex. Retrieving all the dependencies should be automated. Using these dependencies to build a consistent batch does not support errors. Avoid manual action, there is no added value there for these boring (and error prone) activities. There are a lot of devops software, let them do the job.
At this step, we recommend the relationship should not add true constraints to the database, and triggers never return any error. But trigger can send messages (to developpers, not to users) to signal the application has a problem. This problem is currently a warning, but will soon become an exception (a blocking error) and should be solved in time.
The existing application continues to work correctly, completely ignorant of all these new fields and new tables.
This is particularly true in our example application at the step where the code decide to replicate or not replicate the changed ClientP address to table OrderP.
Explanation. When the existing application change a client address, it is forbidden to have in the new database another process that do this replication to orderT table because
· either it is already done by the existing application,
· or this surely create undesired reaction of the existing application … because sometimes it should not be done.
5.5. Conclusion
Mainly, in each child table, the process to add relationships to the database adds insert trigger and update trigger for each relationship.
The RPG programs continue to work. Magic isn't it?
6. Prepare database to the new languages
For example, the web (java/php/node.js/javascript/…) version of the application.
6.1. Executive summary
New languages or new practices mean new knowledges, new know-hows. It is time to include in the team, temporarily or permanently, people with the right knowledge to avoid basic mistakes to the current team.
6.2. Introduction
In this chapter we will explore the foundation of the new application. It's all architecture.
Clearly: try to answer a few to what, who, where, when, how, how much, why.
The most difficult task here is the new paradigm: instead of the spaghetti code, we ask for a better separation of the various knowledges that are today running in the same head(s):
1) database administrator
2) Database architect
3) Business rules architect
4) User Interface engineer
6.3. Database administrator role
The database administrator only decide who can use/change data (no care of structure, just data).
This person is in permanent relation with business: the theoretical owner of the data is the business, but allowing or denying authorizations is a technical operation done by the database administrator … which is not a member of the business team.
Examples of business rules that are candidates for RCAC:
- Only a small set of employees can work with VIP customer data (and there is a VIP status in customer file ClientP). That is to say, hide some rows depending on status.
- Only accounting employees can see the credit limit. That is to say, hide this column depending on employee job.
6.4. Database Architect role
The database architect is the guy that choose how the database is organized, and how it evolves. (See definition by Mike Cain at http://db2fori.blogspot.fr/2012/11/db2-for-i-database-engineer-description.html).
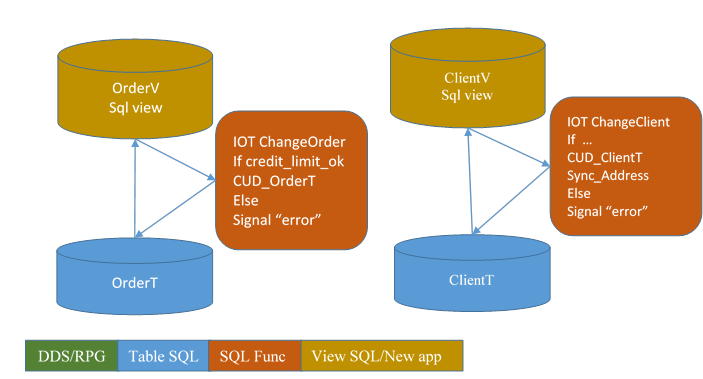
To be able to do the job, he should provide views to the business rules architect, so when database will change it is highly probable that the views will not change.
In our example, he creates the views OrderV and ClientV, for use by the new application
By this providing a layer of abstraction.
In our example, this will allow the database architect to decide when the table AddressT will be populated, and simultaneously decide to drop the original columns in ClientT and OrderT tables.
He provides to the business architect
· Either the insert/update/delete statement on OrderT
· Or the function CUD_OrderT (for Create Update Delete Order). The function contains the necessary DML statements (insert, update, delete).
CUD functions creates a better level of abstraction.
6.5. Business architect
The business architect is the guy that integrate the business rules in the database. That is to say, he is responsible of protecting database from forbidden change, without any care to the program used to run the change (a legal program, or not)(unrelated to the compiler).
In our case, he is the guy that
- Uses the views OrderV and ClientV to get application information
- Adds the rule “Credit Limit OK” in the SQL function that create or change an order in the view OrderV. This function is an IOT (instead of trigger), the tool to control changes to a view.
Current application ignores these new views. Current application requires a format and an index. The view does not provide an index.
6.6. User Interface engineer
The User Interface engineer uses the OrderV view to read data from the Order table and edit them so they appears correctly to the user, following the design prepared by the user interface designer.
He uses the same view to update these data from the user interface.
In our case, it is the web application.
6.7. Conclusion
A this step, the OrderV view present the address either from the OrderT table or from the AddressT table, depending on the decision of the DB Architect to populate table AddressT. The new application is already ready to work with AddressT table, because it is totally ignorant of where is stored address data: no change to do when the data will be deduplicated.
At this time in table AddressT there is nothing, table is empty. The address data are still not deduplicated.
Why? Because the existing RPG application continues to use the DDS-LF OrderP, and this updatable LF needs the corresponding columns to be in the table OrderT (rendering population of table AddressT useless).
Same thing for DDS-LF ClientP.
When address is changed in ClientV (by the new application), it is the task of the database to decide to replicate or not the change to table OrderT, depending on business rules (allowed/forbidden for any reason). This task is currently coded also into the existing application, which uses the DDS-LF ClientP.
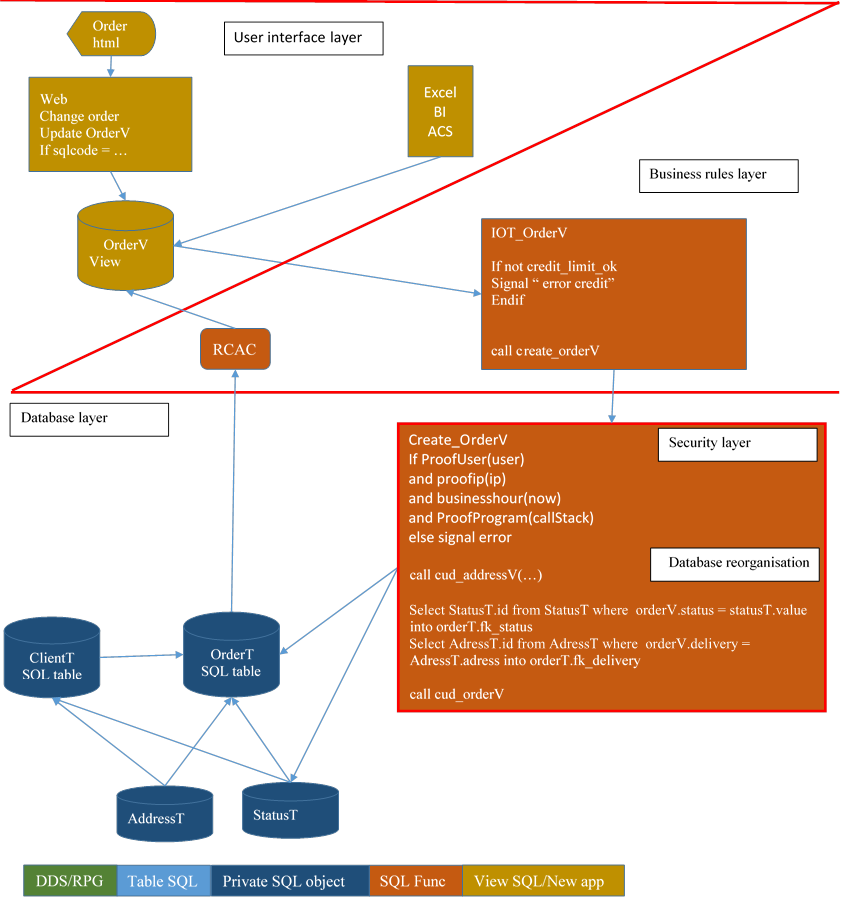
6.8. The abstraction layers begin to appear
While Migrating image:
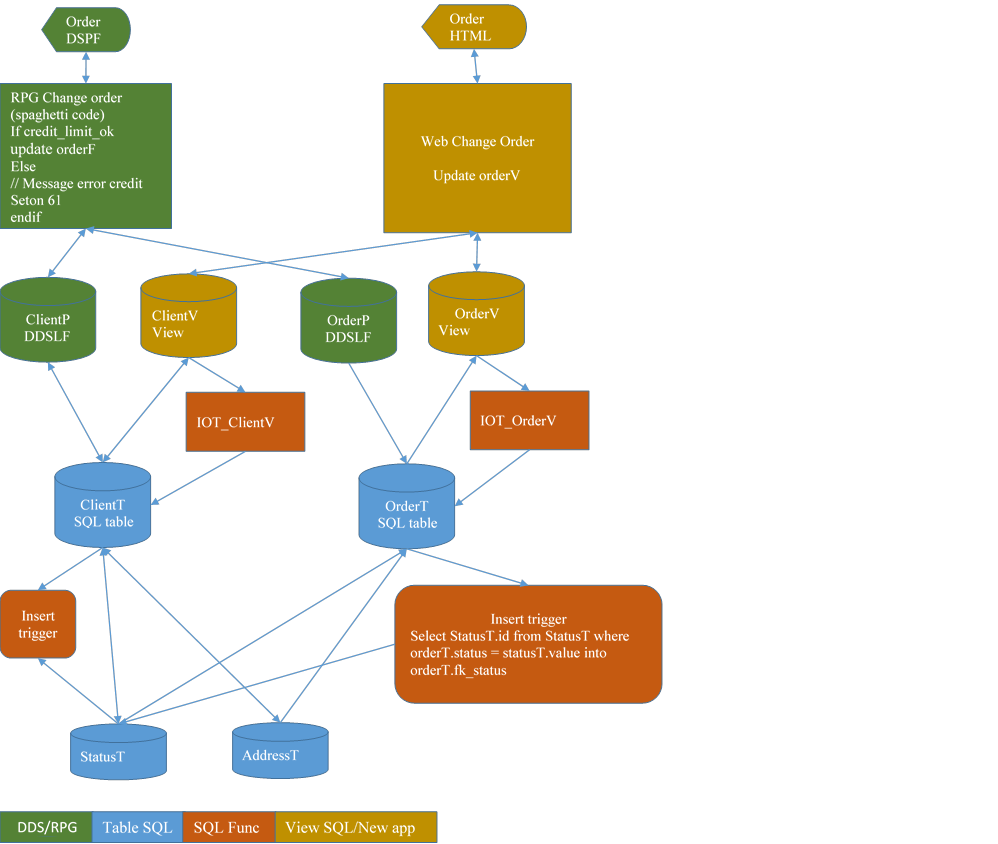
7. Complexity implicit or explicit?
7.1. Executive summary
Normalization force developer to create things more consistent, simpler and smaller. Side effect: splitting old large things means more little things to handle. There are tools to handle so many little things, able to never forget one.
7.2. Introduction
Why do we need so much objects?
Would not it be simpler to connect directly the new application to the new table?
No.
Making simpler objects and attach them to a precise layer of architecture is easy.
It is the interest of having smaller objects.
Implicit complexity: hidden in spaghetti code
Explicit complexity: visible as a dedicated object (SQL object or System object)
7.3. Case 0: no view + new program is monolithic (spaghetti code)
The new application reproduce the same architecture as the old one. It is easy to map the new one to the old, and is supposed to make maintenance easier. Just two times the same maintenance.
Problem: the integrity of the database is still out of the database.
Note: the new tables are private. In other word, public access is excluded.

7.4. Case 1: new program less spaghetti – less code, more consistency
Database integrity (maintenance of foreign keys) is into the database: by no way, a process can add an inconsistent order in the table OrderT.
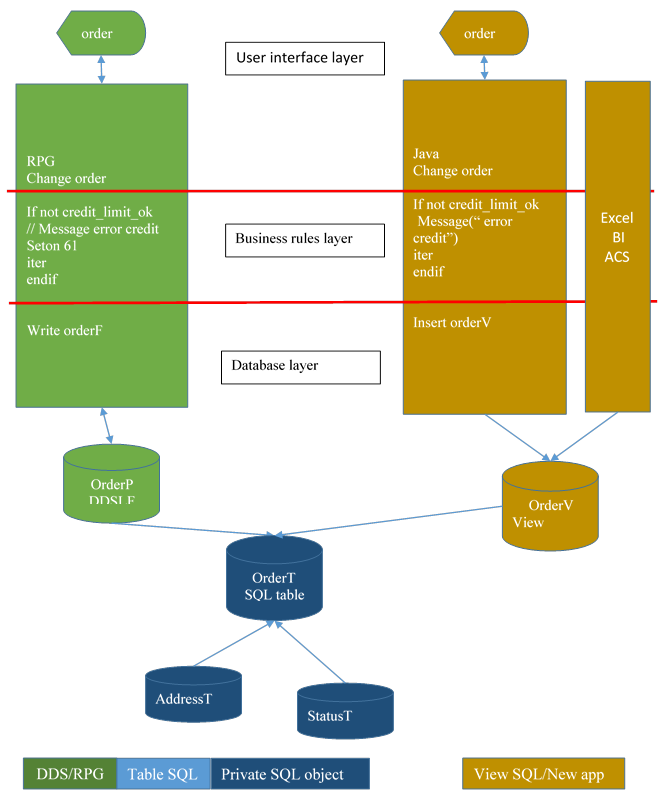
7.5. Case 2: business constraints in the database – less code more quality
Database and business integrity is in the database. We have achieved a large evolution of the database, and the new business function makes applications simpler to create. But there is still something missing.
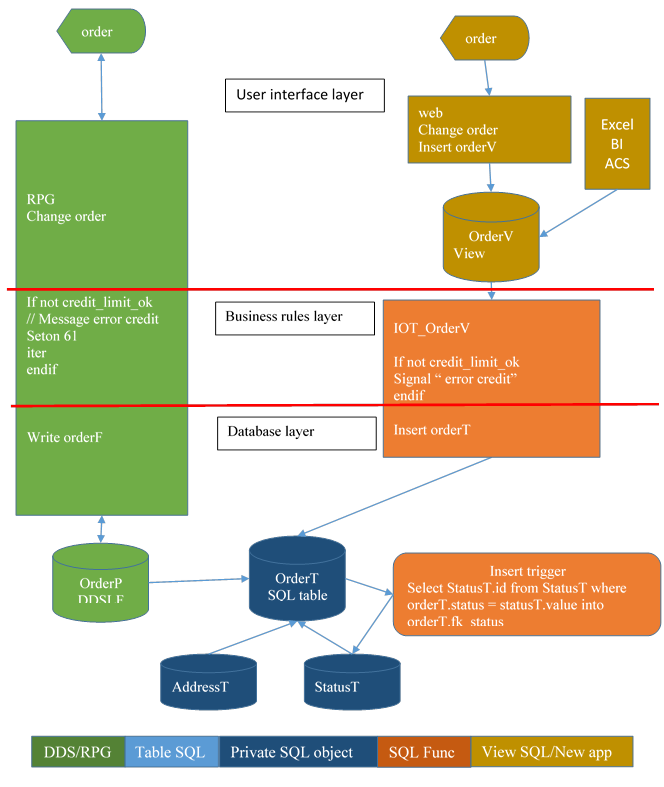
7.6. Case 3: business constraints and security constraints in the database- more security
It is now easy to add a security layer integrated in the database.
 Conception of security is supposed to be included in the conception
of the application, since the early days.
Conception of security is supposed to be included in the conception
of the application, since the early days.
The purpose is to be able to filter user action on information not related to the database: if a user (that is to say, someone having (stolen?) profile and password) is working from a verified IP address, during business hours and via a program of the application, the security layer let the action to be continued.
Native authorities (if handled correctly) are necessary but not sufficient.
if you see that the CFO is DFUing the file for bank transfers on december 31st at 3am from china, you can conclude that someone in your neighborhood who has been discreetly watching you for a long time has just taken action. It embezzles your funds.
Database, business and security integrity is into the database.

But table AddressT is still empty.
8. Prepare the old code
8.1. Executive summary
After the database, it is time to decide about current application. Will you preserve the old app? if yes, how ?
A few options exist.
You should do an inventory of current situation before launching any evolution project.
8.2. Introduction
In this chapter we will explore what can be done in existing application, if it is decided to keep it alive.
Possible? Yes. Expensive? Yes. Utility? None (no new feature for users). Mandatory? No.
The prerequisite to reorganize the database is that the DDS-LF OrderP and ClientP should disappears.
Preserving the existing programs means they stop to use the DDS-LF OrderP and ClientP and use sql views instead.
Target: being able to move a column from one table to another without impacting the application.
8.3. RPG-OA Open Access architecture Hypothesis
RPG-OA is a RPG4 feature created to access non-database strange things such as an html page by simulating an *FILE object.
Prerequisite: all programs are RPG4, and source code is valid (can recompile). Have you RPG3 or CL using files?
At first glance, using it to hide the new table organization in a program seems elegant.
But not.
Reason: Moving RLA I/O to external modules will probably give something like that:
One OAH (Open Access Handler) module per file and per open mode (that is to say, with handle of locks or not)
BTW, do you remember how locking works in RLA? (RPG code), and how to handle that in state less applications? (With the optimist lock based on the update timestamp)
Effect: just one more spaghetti.
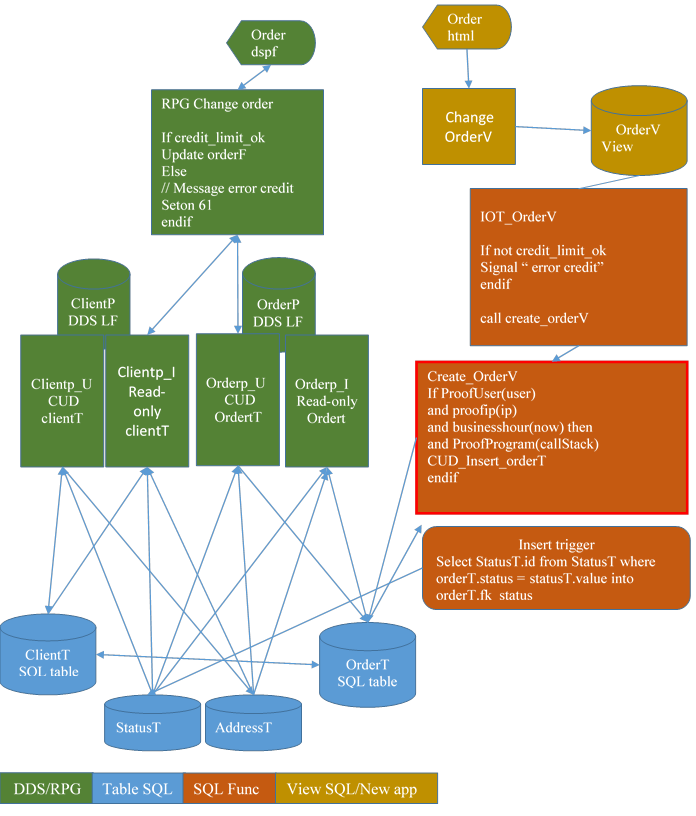
8.4. One solution: dive deeply into the old code
The minimalist option is to replace, If possible, when possible, the
RPG:
CHAIN … ORDERF
UPDATE ORDERF
By
SQL:
SELECT … FROM ORDERV … FOR UPDATE
UPDATE … ORDERV … WHERE CURRENT OF mycursor
Complementary option: remove the verification that are now supplied by the database integrity … and replace it by handling the error returned by the SQL UPDATE. Not sure it is very efficient.
Think that you will have to convert the sql error code in an appropriate error message to the user.
Possible? Yes. Expensive? Yes. Utility? None. Mandatory? No.
But there is no risk (and limited cost) to handle new errors promoted by the Instead Of Trigger: just replicate in RPG syntax just after the SQL UPDATE, exactly what you just add in the web application just after the same SQL UPDATE.
Programs are changed to use SQL DML (select delete insert and update) on OrderV.
DML = data manipulation language https://en.wikipedia.org/wiki/Data_manipulation_language
DDL = data definition language https://en.wikipedia.org/wiki/Data_definition_language
DCL = data control language https://en.wikipedia.org/wiki/Data_control_language
DQL = data query language https://en.wikipedia.org/wiki/Data_query_language

8.5. Can I add new constraints?
 Both in new and old app. That is true for constraints or new
conditions: the Instead Of Trigger will receive database reactions against
integrity constraints, referential constraints, unicity constraints and new
business constraints (IE new condition). The IOT will then promote that with a
signal to the caller.
Both in new and old app. That is true for constraints or new
conditions: the Instead Of Trigger will receive database reactions against
integrity constraints, referential constraints, unicity constraints and new
business constraints (IE new condition). The IOT will then promote that with a
signal to the caller.
The caller has to manage it, and promote to the final user a message understandable.
9. Reorganize the database
9.1. Executive summary
The database is normalized, modernized, consistent, and more efficient. In one word: maintainable. Preferably with tools.
We don't know someone maintaining their database manually.
9.2. Introduction
This is the final step of our modernization path.
We have now totally isolated the database from the user interface with enough layers. We can optimize the data into the database,
And the alert triggers (the ones that signal referential integrity errors due to programming problems) don't send us anything for a long time.
Meaning: the applications are now correctly handling referential constraints.
9.3. OrderP
Prerequisite: none of the existing programs use the DDS-LF OrderP.
Target: start populating file AddressT
Actions:
· Drop file DDS-LF OrderP
· Populate file AddressT (a distinct select of ClientT and OrderT)
· Refresh in OrderT the FK to AddressT for Delivery address and Invoice Address.
· Change implementation method of the relationship between AddressT and all its childs
Effects:
view OrderV (and lf OrderP) provides order info, including addresses. This does not change
Before:
· Table OrderT contains columns for Order details, Delivery Address and Invoice Address
· The IOT (instead of trigger) via the CUD on OrderT, updates all the order information.
|
OrderNo |
Custno |
Custname |
Status |
Address1 |
Address2 |
City |
AddressFK |
|
12 |
3 |
Smith |
A |
Champs elysées |
|
Paris |
null |
|
24 |
45 |
Arthur |
X |
Foch |
|
Paris |
Null |
AddressT (empty)
|
ID |
Address1 |
Address2 |
City |
Target:
· move address columns from OrderT to AddressT
OrderT
|
OrderNo |
Custno |
Custname |
Status |
AddressFK |
|
12 |
3 |
Smith |
A |
1 |
|
24 |
45 |
Arthur |
X |
2 |
AddressT
|
ID |
Address1 |
Address2 |
City |
|
1 |
Champs elysées |
|
Paris |
|
2 |
Foch |
|
Paris |
Changed:
· Table AddressT is now populated (with a select distinct address on table OrderT). This operation may be done at any time.
OrderT (unchanged)
|
OrderNo |
Custno |
Custname |
Status |
Address1 |
Address2 |
City |
AddressFK |
|
12 |
3 |
Smith |
A |
Champs elysées |
|
Paris |
null |
|
24 |
45 |
Arthur |
X |
Foch |
|
Paris |
Null |
AddressT (populated)
|
ID |
Address1 |
Address2 |
City |
|
1 |
Champs elysées |
|
Paris |
|
2 |
Foch |
|
Paris |
· Change the IOT of OrderV to
o use the CUD OrderT to update updates all the order information
o use the CUD AddressT to update the delivery and invoice addresses
o refresh OrderT's FK to AddressT
This operation requires exclusive use of OrderT, it is very quick.
· FK in OrderT to AddressT are updated (reapply the maintenance trigger on OrderT). This operation may be done at any time.
OrderT (updated)
|
OrderNo |
Custno |
Custname |
Status |
Address1 |
Address2 |
City |
AddressFK |
|
12 |
3 |
Smith |
A |
Champs elysées |
|
Paris |
1 |
|
24 |
45 |
Arthur |
X |
Foch |
|
Paris |
2 |
AddressT (unchanged)
|
ID |
Address1 |
Address2 |
City |
|
1 |
Champs elysées |
|
Paris |
|
2 |
Foch |
|
Paris |
· Change the IOT of OrderV to
o use the CUD OrderT to update only order details
o use the CUD AddressT to update the delivery and invoice addresses
o refresh OrderT's FK to AddressT
· And drop the insert and update triggers in OrderT, the ones that was maintaining the FK under the cover.
These 2 operations requires exclusive use of OrderT, it is very quick.
· Drop addresses columns in OrderT, and activate the referential constraint
This operation requires exclusive use of OrderT, it is a long operation.
OrderT (reorganized)
|
|
Custno |
Custname |
Status |
AddressFK |
|
12 |
3 |
Smith |
A |
1 |
|
24 |
45 |
Arthur |
X |
2 |

AddressT (unchanged)
|
ID |
Address1 |
Address2 |
City |
|
1 |
Champs elysées |
|
Paris |
|
2 |
Foch |
|
Paris |
9.4. ClientP
Do the same thing for DDS-LF ClientP: select distinct address from client where not exists in addressT
9.5. Table StatusT
The code of the triggers that was maintaining the FK from ClientT and orderT to StatusT may be moved to the IOT.
Not mandatory but more elegant.
9.6. Permissions and masks
Maybe you will add RCAC (Permission and Mask) to your files.
RCAC is a security layer at SELECT step
Row access control give control on who can read records. For example the VIP clients.
Column access control give opportunity to mask a field value. For example, the credit limit.
9.7. Impacts
Nothing changes for the Interface architect?
Not exactly. The underlying changes are large. Even if the business layer code (the IOT) is supposed to works as is, verifications are mandatory. It's time for non-regression testing.
Good job
The database is normalized and secured
The application is renewed
You are modern! Welcome to this century.
Remerciements
Un grand merci à Thierry LABRUNIE pour les nombreuses matinées passées à peaufiner ce document.